





«Noi di Microsoft vi garantiamo che i vostri dati resteranno davvero vostri. La privacy è un diritto umano». Quando il Ceo di Microsoft Satya Nadella ha detto così dal palco della Build, la conferenza di sviluppatori andata in scena a Seattle a inizio maggio, non è scattato l’applauso. Così come sono rimasti tiepidi i pubblici delle conferenze di Google e Amazon Web Services di fronte agli appelli dei propri manager a «etica» e «responsabilità», a uso e consumo più della stampa che dei propri sviluppatori. In fondo l’attesa di eventi che costano più di 2mila dollari all’ingresso è quasi sempre rivolta agli annunci più tecnici, dall’aggiornamento dell’ultima versione di Windows 10 alle nuove funzioni di Android. Questione di prospettive. Per i vertici dei colossi Web, i richiami alla trasparenza sono un rituale necessario per garantirsi la materia prima più preziosa: i dati, le informazioni degli utenti che fanno da carburante nel settore del cloud computing (i servizi di calcolo distribuiti online). Senza la fiducia dei clienti le «nuvole informatiche» si svuotano dell’unico contenuto che le tiene in piedi. Forse non è una guerra, ma di sicuro la competizione è accesa.
Un business decisamente promettente
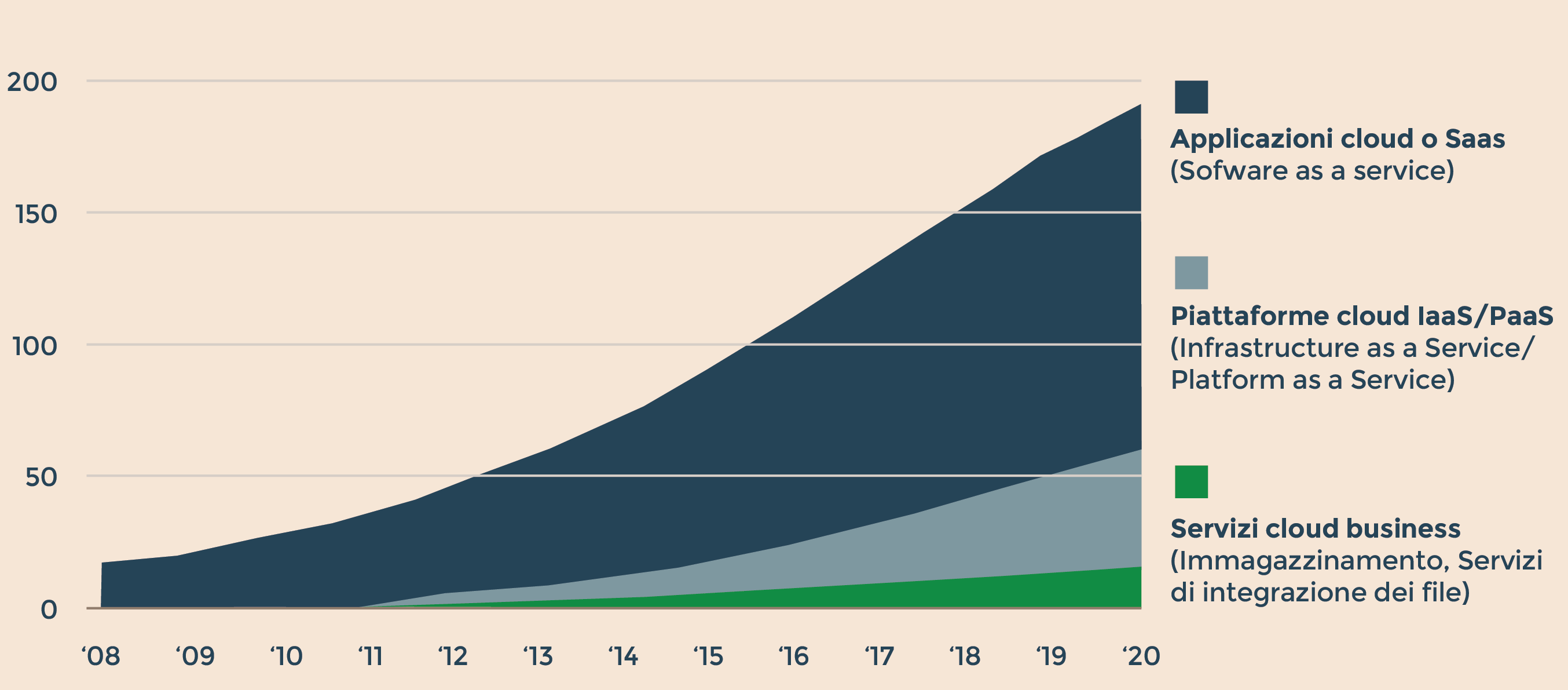
Forrester Research, una società di ricerca, si spinge a prevedere un giro d’affari globale del cloud pari a 191 miliardi di dollari entro 2020. Ricavi che si distribuiscono fra vari sottoinsiemi dell’industria: le cloud applications (meglio note come Software as a Service, i servizi software accessibili dal Web via abbonamento), Infrastructure as a Service (le infrastrutture digitali al servizio delle imprese, dallo spazio virtuale sui server alle connessioni di rete ) e i servizi cloud per il business (come il classico storage, l’archiviazione dei dati).
Amazon Web Services (Aws) ha sotto mano circa il 47% del mercato del public cloud, il servizio di immagazzinamento dati più popolare fra le aziende. La divisione, in proporzione più redditizia dell’e-commerce della casa madre Amazon, ha messo a segno circa 5 miliardi di ricavi nel primo trimestre e oltre 17 miliardi di dollari nell'intero 2017.
Si stima che gli acquisti di public cloud a livello globale passeranno dai 72 miliardi di dollari del 2014 a 191 miliardi nel 2020. In miliardi di dollari
(Fonte: Forrester Research)
Microsoft conta oggi “solo” sul 10% del mercato globale del public cloud, ma i suoi ritmi di crescita danno le vertigini. Nel primo trimestre del 2018, quasi 8 dei 26,8 miliardi di ricavi complessivi sono arrivati dall’intelligent cloud, la gestione dati integrata da tecnologie di intelligenza artificiale. La sola piattaforma Azure è cresciuta di oltre il 90%, contro il 45% circa di espansione di Aws.
E Google? La divisione cloud di Alphabet, la parent company del motore di ricerca più popolare del mondo, oggi spunta sul terzo gradino del podio con una quota del 3,9% del mercato. Ma è anche vero che Big G si può permettere ritmi più blandi, perché i suoi 110 miliardi di dollari di fatturato sono distribuiti fra più settori, come l’advertising e il sistema operativo Android. I profitti più robusti arrivano dalla pubblicità, mentre sia Amazon che Microsoft hanno trovato nelle «nuvole» una miniera destinata solo a espandersi. Va bene parlare di assistenti virtuali e consegne con i droni, ma per ora i soldi veri si macinano convincendo le aziende a depositare informazioni sensibili sui propri server. «Quello che ci interessa è la fiducia dei clienti» ripetono i manager Microsoft, tanto per ribadire il concetto che le imprese devono fidarsi e delegare a loro i propri dati.
Ovviamente, la corsa all’accumulo di informazioni non è fine a se stessa. La supremazia dimensionale sui concorrenti è lo strumento che permette a tutte le aziende di rielaborare e monetizzare meglio i dati in proprio possesso, offrendo alla clientela strumenti di analisi più sofisticati. Ed è qui che entra in gioco la sfida dell’intelligenza artificiale, le tecnologie che simulano l’intelligenza umana. Sempre Microsoft, Google e rivali parlano in maniera inesausta di machine learning (la branca dell’Ai che istruisce le macchine ad apprendere in maniera automatica) e deep learning (detta in maniera semplice, il salto di qualità che fa imparare ai computer a riconoscere testi, immagini e suoni). Microsoft lancia kit per sviluppare soluzioni di Ai sul sistema operativo Windows, Google integra il machine learning sulla piattaforma mobile Android, Amazon Web Services insiste sugli assistenti virtuali. Al di là delle vocazioni più avveniristiche, l’obiettivo comune fra i vari servizi di Ia è sempre lo stesso: elaborare in maniera più rapida e precisa la informazioni online, servendosi di machine learning e deep learning per scremare i contenuti e trasformarli in servizi spendibili dalla pubblicità alle ricerche di mercato. Il problema è che il miglioramento qualitativo dei software va di pari passo all’aumento quantitativo di dati. Più “petrolio” si inietta nelle macchine digitali, migliore sarà la sua raffinazione. «Il target vero di queste aziende – spiega Diego Lo Giudice, analista di Forrester Research – non è di ammassare dati e basta. Ma di portarsi carichi di lavoro sempre maggiori sul proprio cloud e migliorare il livello degli algoritmi».
Rastrellatori di dati
La fame di dati è familiare a un altro colosso della costa ovest degli Usa: Facebook. Il social network di Mark Zuckerberg fa vita a sé, perché il suo business è vendere la (nostra) attenzione agli inserzionisti pubblicitari. Eppure la materia prima che alimenta i suoi 5 miliardi a trimestre di utili sono sempre le informazioni sui suoi utenti, anche se raccolte con una strategia che non ha nulla a che spartire con il modello sposato dagli altri colossi online. Facebook, come ogni social network, non fa pagare il suo prodotto perché gli utenti sono così generosi da regalargli tutto quello che gli serve per espandersi: una finestra aperta su se stessi, i propri interessi, i propri problemi.
Magari anche le proprie inclinazioni di voto, come ha spiegato bene il caso di Cambridge Analytica e la consapevolezza, improvvisa, che anche un like cliccato d’istinto rivela una parte di noi agli algoritmi di Zuckerberg. Facebook, al tempo stesso, è il marchio più pervasivo e vulnerabile rispetto alla concorrenza. Più pervasivo perché si infila ovunque, arrivando a un grado intrusività che il cosiddetto datagate ha solo fatto emergere con più chiarezza, contribuendo – la notizia è di ieri – alla disattivazione nel primo trimestre dell’anno di circa 583 milioni di profili falsi e 837 milioni di contenuti spam. Più vulnerabile perché la sua forza, le informazioni sugli utenti, può trasformarsi in una condanna nel momento in cui gli utenti decidano di abbandonare la piattaforma che custodisce l’io pubblico (e privato) di un totale di iscritti numerosi quanto la popolazione di Stati Uniti, Cina ed Europa messe insieme.
Le regole saranno uguali per tutti?
L’intera filiera del web dovrà confrontarsi con un ostacolo che accomuna i servizi B2B di Microsoft e «le foto sul diario» di Facebook: il Gdpr, il regolamento europeo sui dati in arrivo il 25 maggio. Il testo fissa paletti molto rigidi su temi come la richiesta di consenso e il diritto all’oblio, la rimozione definitiva di dati a proprio riguardo. Per i trasgressori scattano multe fino a 20 milioni di dollari o il 4% del proprio fatturato, se supera quella cifra. Ma negli Stati Uniti c’è chi è scettico sulla sua efficacia, o meglio, sulla sua efficacia con i grandi gruppi. «Gente come Microsoft e Facebook – dice Hoelger Mueller, vicepresidente di Constellation Research – ha avuto tempo e risorse per attrezzarsi sul piano legale. Lo stesso non si può dire dei piccoli business. Il rischio è che il Gdpr finisca per dare una mano ai big guys, i pezzi grossi».
© Riproduzione riservata