

Storia dell'articolo
Chiudi
Questo articolo è stato pubblicato il 13 gennaio 2013 alle ore 16:00.




È una memoria evanescente nel tempo: la quota di copie delle pagine web custodite all'interno di biblioteche e piattaforme su internet varia dal 30% al 90 per cento. Anzi, la partecipazione delle persone negli spazi pubblici dei social media ha complicato le cose. Dopo due anni il 27% dei messaggi condivisi dagli iscritti alle reti sociali online durante la primavera araba non è più accessibile: sono testimonianze e opinioni scomparse forse per sempre.
È il risultato di due studi della Old Dominion University negli Stati Uniti. Eppure il web allarga i suoi confini senza rallentare: nell'anno appena trascorso i dati pubblicati hanno raggiunto 2,7 Zettabyte, il 48% in più rispetto ai 12 mesi precedenti. Ma a dare filo da torcere per i tecnobibliotecari sono evoluzioni continue nei media, come i social network e le trasmissioni in diretta streaming.
Le arche di Noè che racchiudono le copie del web hanno la forma di armadi: la biblioteca digitale dell'Internet Archive è tra le più ampie al mondo e ospita server capaci di raccogliere finora 10 Petabyte (10 milioni di miliardi di byte, equivalenti a circa 2,1 milioni di dvd da 4,7 Gigabyte), accumulati fin dalla fondazione nel 1996.
Il calore in eccesso generato dall'hardware contribuisce a riscaldare l'edificio nel Richmond district di San Francisco. Nell'anno appena concluso i siti che hanno debuttato online sono stati 78,3 milioni secondo Netcraft: l'Internet Archive ha portato su silicio i duplicati di 50 miliardi di pagine. Il team di tecnobibliotecari scandaglia l'intricata ragnatela di link attraverso una raccolta di dati su larga scala (bulk harvesting) guidata da un esploratore software (crawler) come Heritrix per trovare nel labirinto in espansione di internet altre pagine da preservare. Ma incontra una diga nel deep web, quando ad esempio l'accesso è protetto da password. Oppure, l'archivio della città californiana arricchisce i suoi scaffali digitali mediante accordi con istituzioni e organizzazioni non profit.
La letteratura balinese è diventata la prima interamente consultabile online grazie alla collaborazione con la Wesleyan University. All'Internet Archive si affiancano i progetti delle biblioteche nazionali riunite nell'Iipc (International Internet Preservation Consortium).
Parola chiave: metadati. La Library of Congress di Washington conserva 170 miliardi di messaggi inviati con Twitter, grazie a un accordo per esaminare i micropost dal 2006 con poche limitazioni, adoperato anche dalla Biblioteca nazionale francese. Custodisce i metadati associati ai messaggi: indicano, ad esempio, chi ha risposto o quante volte un tweet è stato inoltrato da altri. Sono una miniera per scavare nelle informazioni (data mining).
E contribuiscono a edificare un web semantico comprensibile alla lettura delle macchine e in grado di fornire risposte a domande complesse. Le stime della conferenza Dmasm di La Jolla valutano che siano 500 miliardi le immagini scattate ogni anno nel segmento consumer: il più grande album del mondo è Facebook e acquisisce in media 300 milioni di fotografie al giorno (circa 109,5 miliardi in un anno). Ma l'accesso pubblico delle immagini è consentito solo se previsto dalle impostazioni per la privacy di ogni iscritto. Sono in fase di test strumenti per raccogliere memorie condivise nei profili personali, attraverso le api (application programming interfaces).
È Google a costruire quasi in diretta la copia del web contemporaneo più aggiornata e ampia. Come se fosse uno specchio capace di replicare l'espansione dell'universo digitale. Nel 2010 gestiva 900mila server distribuiti nel mondo secondo un'analisi di Jonathan Koomey, ricercatore dell'università di Stanford: a partire dal progetto Caffeine ha accelerato lo sviluppo della capacità di mappare il web in tempo reale in modo da aggiornare i risultati delle ricerche online.
L'iniziativa di Spanner abilita la sincronizzazione attraverso gps di database in luoghi distanti del globo. La visione è organizzare l'informazione globale e renderla fruibile al pubblico. Fin dagli inizi ha esplorato le opportunità dell'intelligenza artificiale. Nel dream team di Google è entrato anche Ray Kurzweil, teorico della "singolarità": prevede entro il 2045 l'emersione di una superintelligenza. Che trova radici in una potenza di calcolo condivisa con chi ogni giorno contribuisce alla coevoluzione del motore di ricerca. Anche l'intelligenza artificiale non può fare a meno di essere umana.
Clicca per Condividere

©RIPRODUZIONE RISERVATA
Permalink
Ultimi di sezione
-
APP AND ENTERTAINMENT
Ecco le migliori app per organizzare le vacanze last-minute
di Anna Volpicelli
-
nova24
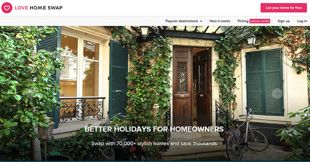
Startup, la mappa delle regioni che hanno ricevuto più finanziamenti dal Fondo Pmi
di Luca Tremolada
-
TREND
Effetto Grecia anche su Google: vacanze e crisi sono il tormento degli italiani
-

Gadget
I Google Glass cambiano faccia: arriva la Enterprise Edition?
-

DIGITAL IMAGING
Fotografia: ecco le migliori app per i professionisti dell'immagine - Foto
di Alessio Lana
-

la app della discordia
UberPop sospeso anche in Francia. E ora in Europa è fronte comune


Dai nostri archivi
Moved Permanently
The document has moved here.