

Storia dell'articolo
Chiudi
Questo articolo è stato pubblicato il 17 febbraio 2013 alle ore 15:07.




Le città. I corpi. Le conversazioni. Sono tre fonti di dati in tempo reale. Alimentano le intuizioni creative di startup e istituzioni pubbliche. Il Commissario delegato per la ricostruzione in Abruzzo ha un sito web dove condivide le informazioni sulla quantità di macerie rimosse durante la giornata: i cittadini online osservano attraverso un grafico i quintali di detriti portati via dal mattino fino alla sera. Secondo le rilevazioni sono state 691mila le tonnellate raccolte dal 2009. Nelle prime due settimane di febbraio erano circa 48mila.
È un pannello di controllo in diretta per monitorare i lavori sul territorio dopo il sisma, anche lontano dai riflettori delle telecamere. Il Trasporto passeggeri Emilia-Romagna (Tper), invece, ha aperto i suoi dati sui trasporti pubblici locali. L'accesso in tempo reale e il riutilizzo da parte di altri all'esterno permette di costruire applicazioni software per consultare, ad esempio, gli orari di arrivo e di partenza su smartphone o tablet. Sono alcuni esempi della filiera dei big open data: si tratta di dati aperti e adoperabili in altri progetti. Saranno parte del dibattito dell'Open Data Day previsto per il 23 febbraio.
I dati geografici sono una sorgente di idee per startup. Helsinki è stata tra le prime città a rilasciare le informazioni del trasporto pubblico in tempo reale. E in poco tempo alcune imprese innovative hanno varato pagine web dove osservare gli spostamenti dei treni in diretta, come in una mappa vivente. Ai big open data guarda anche Tim Berners Lee, inventore del world wide web e promotore del Web Index: a Londra è stato tra i fondatori dell'Open Data Institute (Odi) che sarà un acceleratore per startup capaci di utilizzare i dati aperti e avviare iniziative imprenditoriali sostenibili. L'Italia non è affatto immobile. Seekangoo ha lanciato una mappa per trovare informazioni sugli eventi ancora in corso nei dintorni oppure previsti nei giorni successivi.
Con la diffusione dei big data cambia il rapporto con il corpo che attraverso i gadget indossabili (o wearable electronics) diventa una fonte di dati. La startup Empatica ha progettato e costruito un braccialetto per il monitoraggio diretto di alcuni parametri fisiologici, per esempio il battito cardiaco: le informazioni sono raccolte all'interno di archivi personali online e forniscono indicazioni sulle modalità di miglioramento delle proprie abitudini durante la giornata. Oppure, dispositivi come il contapassi Fitbit e gli occhiali Google Glass alimentano applicazioni capaci di visualizzare i dati e condividerli nei social network in modo da incoraggiare discussioni, mediante le application programming interfaces (Api). Sono processi che contribuiscono alla costruzione di un sé quantificato (o quantified self).
Le discussioni nei social media avvengono in tempo reale, arrivano da molte fonti e generano immensi flussi di dati. Facebook, ad esempio, ingloba circa 500 Terabyte al giorno, secondo stime della scorsa estate: è l'equivalente di 5 miliardi di fotografie archiviate nel social network in 24 ore. Ha elaborato piattaforme software ad hoc per i big data come Corona. Finora, però, le piccole e medie imprese locali non hanno ancora usato strumenti complessi per capire bisogni e opinioni del pubblico espressi nei social media. È un punto di partenza dello spinoff accademico Sharper Analytics dell'Università Milano-Bicocca.
Big data non è più soltanto un argomento di conversazione fra cerchie ristrette. La capacità di analizzarli resta un capitolo aperto. Startup come Kaggle richiamano laureati in matematica e fisica che esaminano vasti dataset attraverso gare di talento. La Whale Detection Challenge varata dalla Cornell University e da Marinexplore, ad esempio, è una sfida per capire in che modo rendere più efficiente un algoritmo per identificare i richiami lanciati dalle balene e indicare alle imbarcazioni nelle vicinanze quali itinerari seguire, evitando collisioni in acqua con i cetacei. Il primo premio è di 8mila dollari.
Quella di Kaggle sarà una palestra per data scientist: sono figure professionali specializzate nell'analisi dei big data.
Non esiste ancora un percorso predefinito, ma dalle offerte di lavoro emerge che alla tradizionale formazione delle lauree scientifiche è utile affiancare la conoscenza dei linguaggi di programmazione più diffusi (ad esempio, C++ o Python) e la capacità di utilizzare software per l'analisi statistica e la gestione di database. Nella Silicon Valley californiana dove si concentrano le aziende hi-tech sono richiestissimi i data scientist. Alcune università, soprattutto negli Stati Uniti, hanno introdotto in via sperimentale corsi e seminari dedicati ai big data. Secondo la piattaforma SciVal Spotlight di Elsevier l'area di «matematica e fisica» è tra i primi cinque settori di competenze innovative dell'Italia, subito dopo la medicina.
Clicca per Condividere

©RIPRODUZIONE RISERVATA
Permalink
Ultimi di sezione
-
APP AND ENTERTAINMENT
Ecco le migliori app per organizzare le vacanze last-minute
di Anna Volpicelli
-
nova24
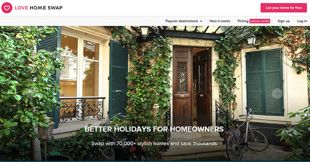
Startup, la mappa delle regioni che hanno ricevuto più finanziamenti dal Fondo Pmi
di Luca Tremolada
-
TREND
Effetto Grecia anche su Google: vacanze e crisi sono il tormento degli italiani
-

Gadget
I Google Glass cambiano faccia: arriva la Enterprise Edition?
-

DIGITAL IMAGING
Fotografia: ecco le migliori app per i professionisti dell'immagine - Foto
di Alessio Lana
-

la app della discordia
UberPop sospeso anche in Francia. E ora in Europa è fronte comune


Dai nostri archivi
Moved Permanently
The document has moved here.