

Storia dell'articolo
Chiudi
Questo articolo è stato pubblicato il 21 ottobre 2012 alle ore 17:34.




Dremel è il titolo di un paper scientifico di Google uscito nel 2010. Chi volesse sfogliarlo lo trova in rete (http://tinyurl.com/c8wdacz) ma non è una lettura rilassante (almeno non per tutti): spiega come compiere ricerche su milioni di gigabytes di informazioni in frazioni di secondo.
Quello studio è stato letto e analizzato da molti se non tutti i computer scientist, informatici e esperti che oggi lavorano o guidano startup attive nel big data. Un gruppo di ingegneri israeliani dopo averlo letto ha programmato OpenDremel, una sorte di clone del Dremel originale. Mike Olson che guida Cloudera una delle più promettenti startup attive su piattaforma open source Hadoop in una intervista a Wired Usa ha consigliato di leggere quel paper per capire il futuro dell'elaborazione di grandi quantità di dati.
Due anni dopo la pubblicazione di Dremel Google ha presentato un servizio web chiamato BigQuery. Consente di usare la piattaforma (attraverso Api o applicazioni di interfaccia) di Google per compiere ricerche su milioni di record senza il supporto di alcun hardware o investimento software. In pratica, l'azienda carica i dati su Google e on demand pagando 3,5 centesimi per GB processato può compiere ricerche interattive usano l'infrastruttura di Mountain View.
Quella dei big data è la metafora perfetta per capire non solo dove sta andando l'It e più nello specifico il cloud ma anche per intuire le mosse di dell'industria dei servizi per le imprese. Per capire meglio questo business, si stima per esempio che Wallmart raccolga ogni ora più di 2.5 milioni di petabytes dalle transazioni che effettua con i clienti. Un petabyte è «un quadrilione di byte ossia l'equivalente di quasi 20 milioni di archivi di testo».
«Big Data è la new big thing – spiega Shailesh Rao, Director New Product & Solutions di Google Enterprise – ma per una piccola impresa significa poter porre domande al proprio business che in passato sarebbero costate troppo. Pensate al vantaggio nel poter interrogare più volte al giorno un mercato che cambia in tempo reale, minuto dopo minuto». Il vantaggio lo ha calcolato Gartner in uno studio uscito questa settimana: nel 2012 questa frontiera ha stimolato una spesa mondiale di 28 miliardi euro, destinati a raggiungere quota 34 nel prossimo anno. «Nonostante l'entusiasmo – scrive Mark Beyer, research vice president at Gartner – big data non è ancora un mercato a se stante». Solo a partire dal 2015, sostengono gli analisti, le organizzazioni cominceranno a inserire le esperienze con big data all'interno delle loro pratiche aziendali. Tre anni dopo pacchetti di soluzioni per trattare grandi moli di dati saranno parte del processo organizzativo delle aziende. Addirittura già si va affermando una nuova figura professionale, quella del data scientist. All'università non esistono ancora corsi ad hoc. Ma sono persone chiamate a ricavare risposte a interrogativi strategici. Loro compito è quindi quello di identificare le fonti di dati, integrarle con altre potenzialmente incomplete ed estrarre dataset su cui poter lavorare. Sul fronte tecnologico già oggi soluzioni di questo tipo sono parte dell'offerta di Emc, Ibm, Microsoft, Hp, Teradata, Oracle, Sap.
Nella testa degli ingegneri di Google BigQuery è solo la parte di una offerta per le imprese (piccole e grandi) che si compone di una serie di servizi cloud e per la collaborazione tra cui Google Storage, Google App Engine e Google Compute Engine. Per Mountain View il loro vantaggio è muscolare, è nella scalabilità di queste tecnologie, nella potenza di elaborazione dei datacenter che Google ha sparsi per il mondo. nelle economie di scala.
«A luglio – racconta Rao con grande soddisfazione – alla conferenza Google I/O, Compute Engine il servizio che permette di utilizzare la infrastruttura di Google per fare girare le proprie applicazioni ha dimostrato di aver accesso a 770.000 core, il supercomputer che analizza il genoma umana arriva fino a 600mila». Tradotto significa avere a disposizione un potenza di elaborazione pari a 96.250 computer (ognuno con una CPU di 8 core). Stime non ufficiali parlano di una dote di un milione di server marchiati Google in giro per il mondo. «La potenza di calcolo non è tutto – spiega però Massimo Casiraghi Responsabile Analytics per l'area Products di Accenture –. Il vantaggio di Amazon e Google non è solo nei datacenter ma anche nell'accesso a internet e social network. Sap e Oracle invece da anni gestiscono i database delle aziende, gli Erp, le buste paga. La promessa di big data è quella di incrociare la montagna di dati in possesso delle aziende con le informazioni di internet. La domanda vera è: si fideranno le imprese a dare "fuori" i loro dati? La risposta passa anche in questo caso da privacy e sicurezza».
Clicca per Condividere

©RIPRODUZIONE RISERVATA
Permalink
Ultimi di sezione
-
APP AND ENTERTAINMENT
Ecco le migliori app per organizzare le vacanze last-minute
di Anna Volpicelli
-
nova24
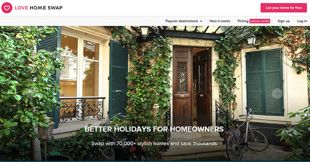
Startup, la mappa delle regioni che hanno ricevuto più finanziamenti dal Fondo Pmi
di Luca Tremolada
-
TREND
Effetto Grecia anche su Google: vacanze e crisi sono il tormento degli italiani
-

Gadget
I Google Glass cambiano faccia: arriva la Enterprise Edition?
-

DIGITAL IMAGING
Fotografia: ecco le migliori app per i professionisti dell'immagine - Foto
di Alessio Lana
-

la app della discordia
UberPop sospeso anche in Francia. E ora in Europa è fronte comune


Dai nostri archivi
Moved Permanently
The document has moved here.